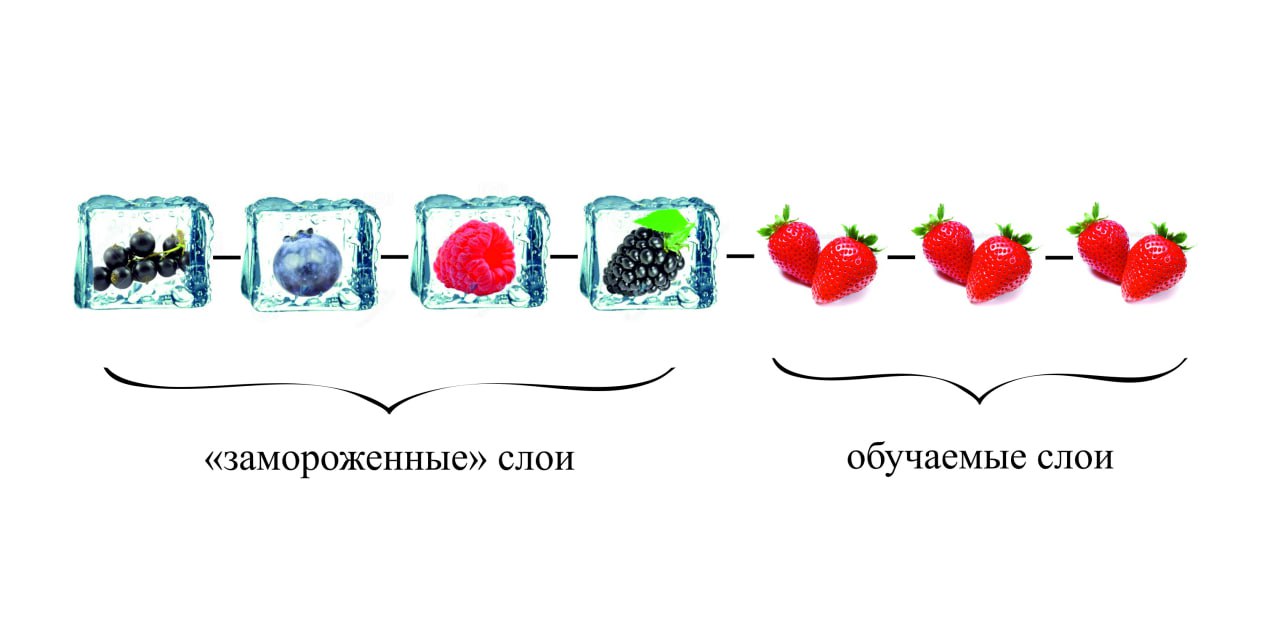
Трансфер обучения

![]()
![]()

Выводы:
- Дообучение (fine-tuning) позволяет использовать общие модели для решения специфических задач.
- Трансфер обучения (трансферное обучение) - это техника использования и дообучения предобученных моделей.
- Позволяет существенно сэкономить ресурсы на обучение моделей.
- Чаще всего применяется для нейросетей, но дообучать можно любые модели.
- При трансфере обучения часть параметров модели может быть зафиксирована (freeze).
- Позволяет использовать малые специфические датасеты.
- Эффективность трансфера зависит от схожести задач.
- Модель может быть обучена надругой задаче, припомощи обучения без учителя или другими произвольными техниками.
Векторизация данных
Выводы:
- Для подачи данных на вход модели машинного обучения они должны быть представлены как вектор действительных чисел.
- Векторизация - процесс преобразования данных из исходного формата в числовой вектор.
- Существует много различных методов векторизации. Для разных задач могут подойти разные.
- Методы векториации зависят от модальности входных данных.
- Векторизация должна как можно более явно представлять значимую информацию из данных.
- Эквивалентно извлечению признаков из данных.
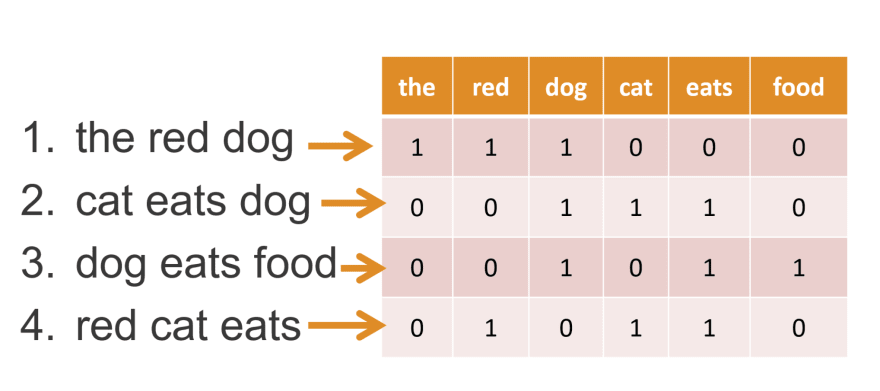
Векторизация естественного текста


1
2
3
4
vectorizer = CountVectorizer()
bow = vectorizer.fit_transform(corpus)
vectorizer.vocabulary_
bow.toarray()
1
2
3
4
array([[0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 1, 0, 1],
[0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 1, 0, 0, 1, 1, 0],
[0, 0, 1, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1],
[1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 1, 0, 0, 0, 0]])
Выводы:
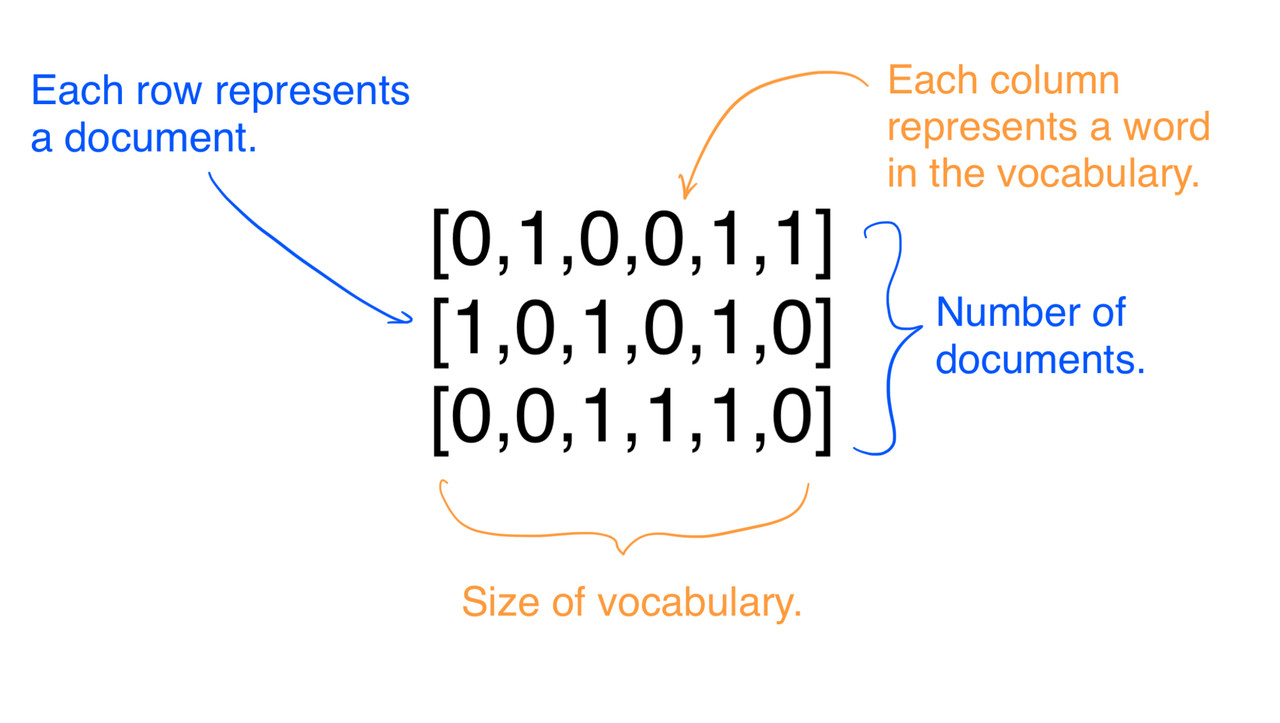
- Есть много разных способов представить текст в виде чисел.
- Мешок слов (bag of words) представляет документ в виде вектора слов.
- Извлекает информацию о частотеслов в тексте. Позволяет сравнивать тематику текста.
- Словарь составляется по обучающей выборке.
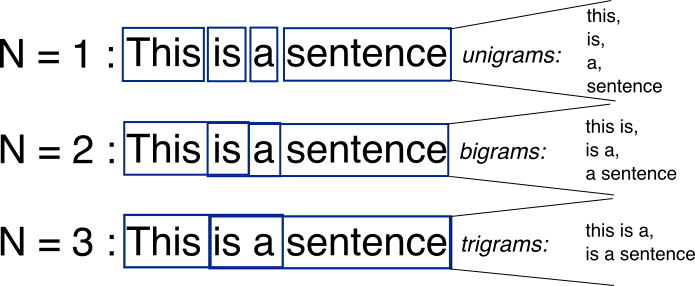
- Для учета контекста часто используются N-граммы. Глубину контекста нужно подбирать.
- На практике вместо слов используются токены.
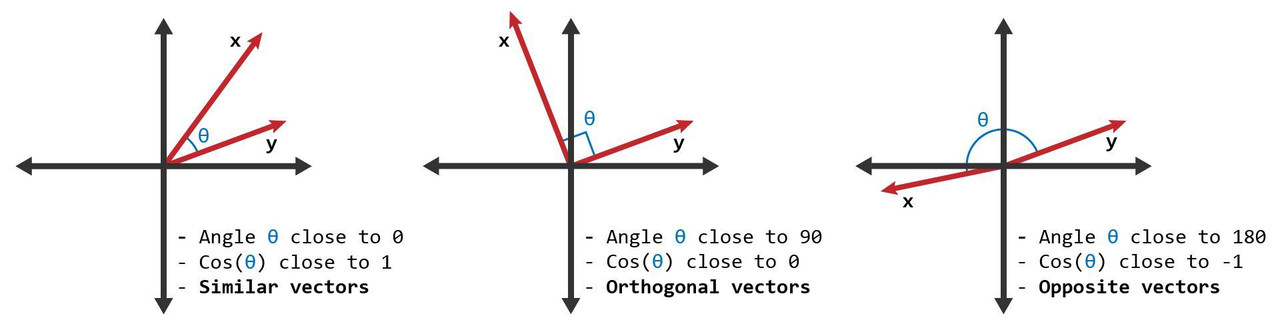
- Минусы - расход памяти, ортогональность токенов, нет учета схожести смысла слов.
- TF-IDF используется для выделения специфических токенов документа, отличающихся от других документов корпуса.
Текстовые эмбеддинги




Выводы:
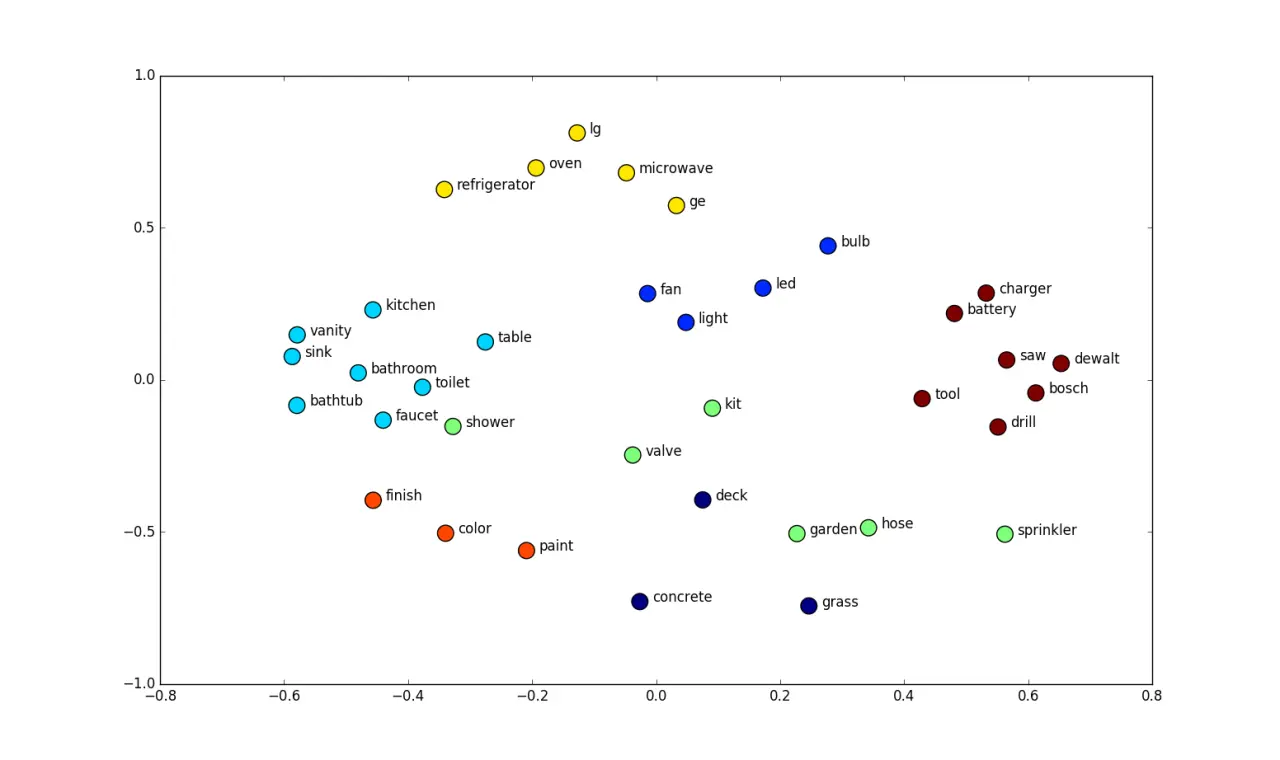
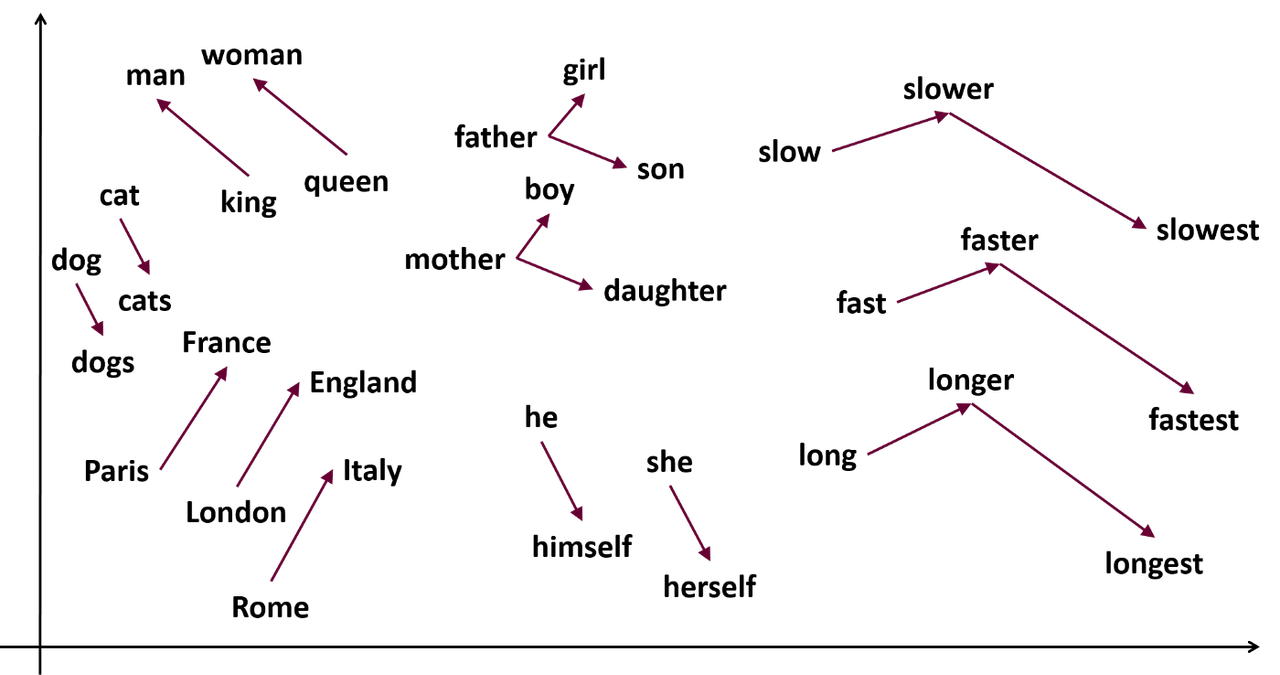
- Текстовый эмбеддинг - это короткое и плотное векторное представление токенов, которое стремится учесть семантику.
- Основываются на гипотезе о том, что семантически схожие слова употребляются в схожих контекстах.
- Используют пространство латентных признаков. Размерность варьируется от 50 до 1000.
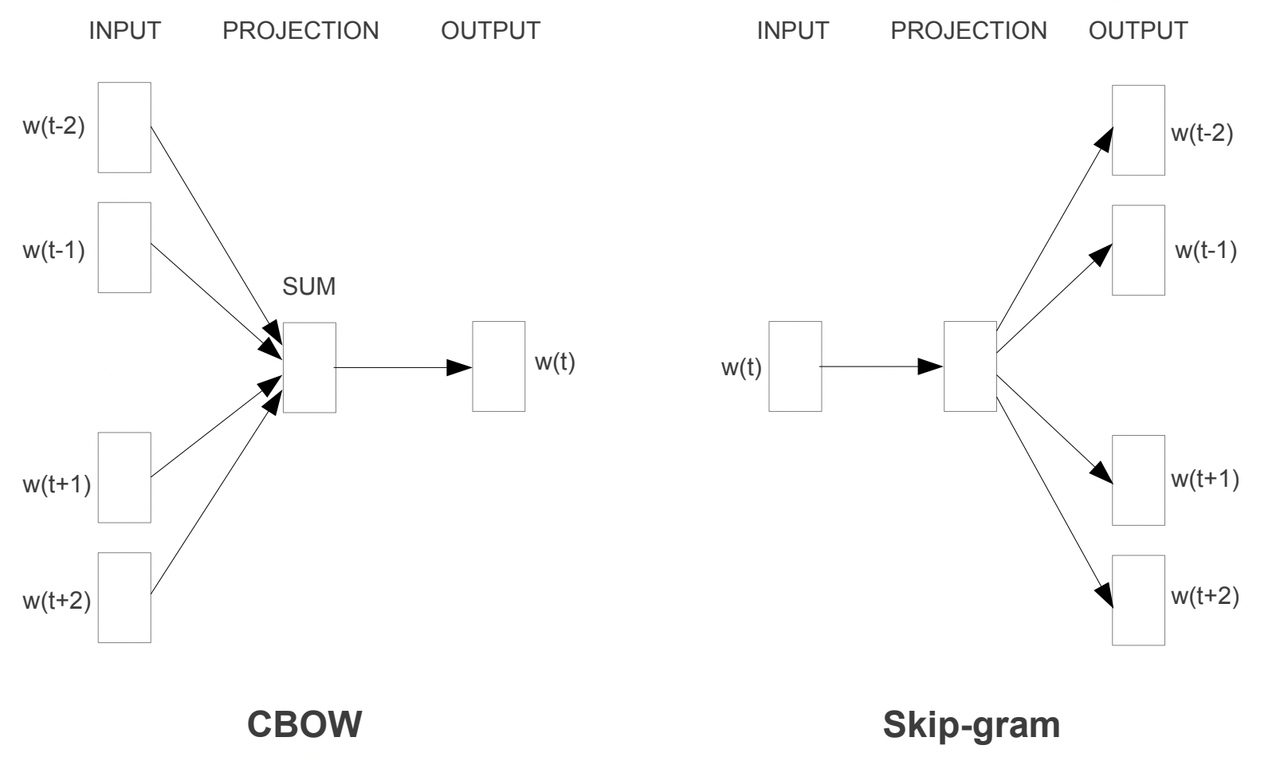
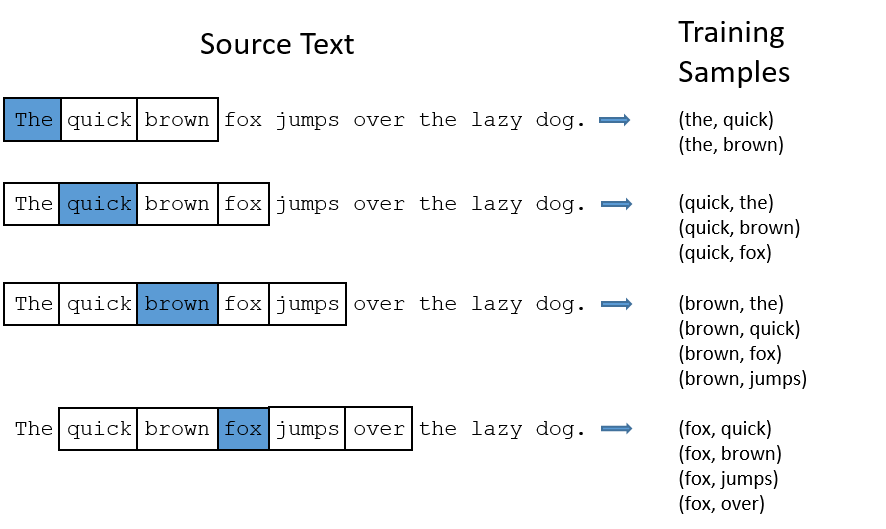
- Модель Word2vec (2013) использует предобученную нейросеть, чтобы получать эмбеддинги с семантическими операциями суммы и разности.
- Word2vec обучается на двух задачах частичного обучения с учителем. Используется для векторизации текстов.
- Текстовые эмбеддинги позволяют существенно повысить эффективность моделей анализа естественных текстов.
- Модель BERT (2018) более сложна и использует нейросеть сложной архитектуры. Контекстно-зависимая. Размерность - 768 или 1024.
Векторизация графических данных
Ансамблирование моделей
Выводы:
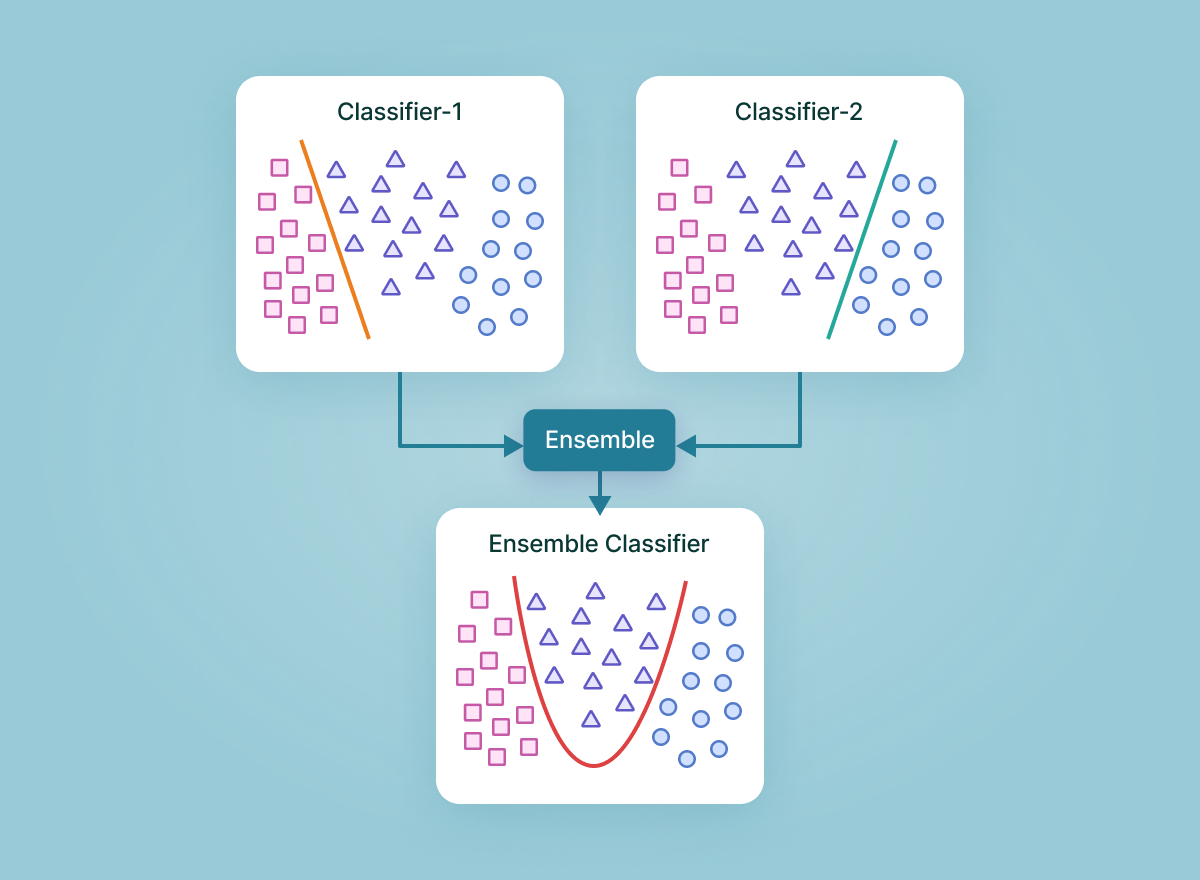
- Ансамблевое обучение - техника обучения нескольких моделей на одной и той же задаче с целью повышения предсказательной эффективности.
- Ансамбль - набор нескольких моделей машинного обучения и способ их комбинирования и обучения.
- Ансамблирование - способ повысить эффективность за счет повышения вычислительной сложности.
- Используется как в обучении с учителем, так и без него.
- Ансамбль выступает как единая модель с входом и выходом. Техника обучения аналогичная.
- Ансамбли также могут переобучаться и недообучаться.
- Работает закон убывания отдачи в построении ансамбля.
Беггинг

1
2
3
4
5
6
7
8
clf1 = LogisticRegression(random_state=1)
clf2 = RandomForestClassifier(n_estimators=50, random_state=1)
clf3 = GaussianNB()
eclf = VotingClassifier(
estimators=[('lr', clf1), ('rf', clf2), ('gnb', clf3)],
voting='hard')
1
2
3
4
5
6
7
8
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
tree = DecisionTreeClassifier()
bagging_clf = BaggingClassifier(base_estimator=tree,
n_estimators=1500,
random_state=42)
bagging_clf.fit(X_train, y_train)
Выводы:
- Беггинг (Bagging, bootstrap aggregating) - метод обучения нескольких моделей на подвыборках обучающей выборки.
- Обучающая выборка разделяется на подмножества с повторениями. На каждом подмножестве обучается своя модель.
- Комбинирование предикторов осуществляется усреднением либо голосованием.
- Беггинг без ресемплинга - это простой голосующий ансамбль.
- Голосование может быть жестким или мягким.
- Существенно уменьшает вариативность моделей. ТАким образом борется с переобучением (ошибки усредняются).
- Итоговая модель менее чувствительна к аномалиям и ошибкам в данных.
- Обучение предикторов можно распараллелить.
- Минусы - потеря интерпретируемости, вычислительная сложность.
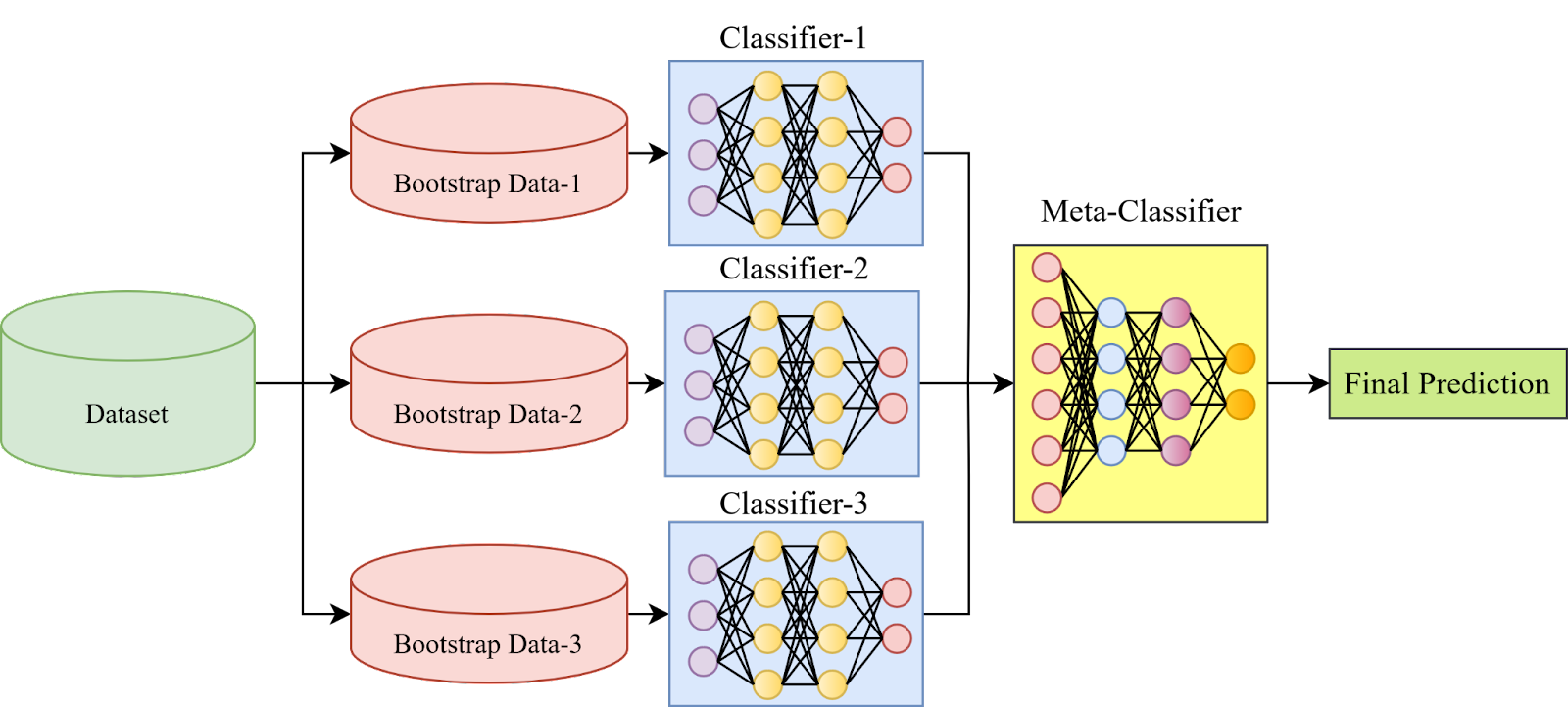
Стекинг
1
2
3
4
5
6
7
8
9
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.ensemble import StackingRegressor
final_estimator = GradientBoostingRegressor(
n_estimators=25, subsample=0.5,
min_samples_leaf=25, max_features=1,
random_state=42)
reg = StackingRegressor(
estimators=estimators,
final_estimator=final_estimator)
Выводы:
- Стакинг (стекинг, stacking, Stacked generalization) - аналогично беггингу, но с добавлением метапредиктора (модель второго порядка).
- Метапредиктор использует выходы ансамблевых предикторов как входные данные.
- При стекинге используется разбиение обучающего набора на K фолдов, как при кросс-валидации.
- Из-за комбинации преимуществ разных моделей способен существенно повысить точность.
- Обучается дольше из-за органиченности параллелизации.
- Склонен к переобучению из-за наличия модели второго порядка.
Бустинг


Выводы:
- Идея бустинга - в последовательном анализе данных моделями из ансамбля.
- Первая модель ансамбля обучается на всей выборке.
- Следующая модель получает лишь те данные, на которых предыдущая модель ошиблась.
- Последующие модели могут исправлять ошибки предыдущих.
- Моделям присваиваются веса в зависимостиот их эффективности.
- Может понижать смещение моделей.
- В качестве предикторов обычно берутся простые модели с высоким смещением и низкой вариацией.
- Из-за последовательной обработки данных, вычислительно сложен.
- Чувствителен к выбросам и аномалиям.
Случайный лес
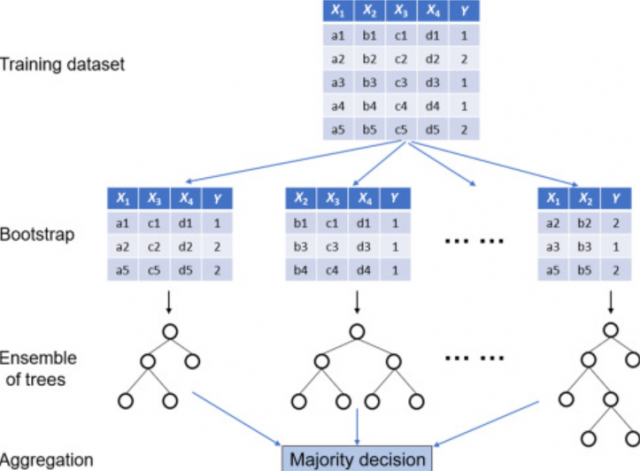
Выводы:
- Случайные лес - это беггинг над набором деревьев решений.
- Деревья решения имеют высокую вариацию, которую может снизить беггинг.
- В случайном лесе обычно используется семплирование как по строкам, так и по столбцам.
- Используется как для классификации, так и для регрессии.
- Менее подвержены переобучению.
- Чем больше количество дереьев, тем больше регуляризационный эффект.
- Можно настраивать максимальное количество признаков для индивидуальных деревьев.
Градиентный бустинг
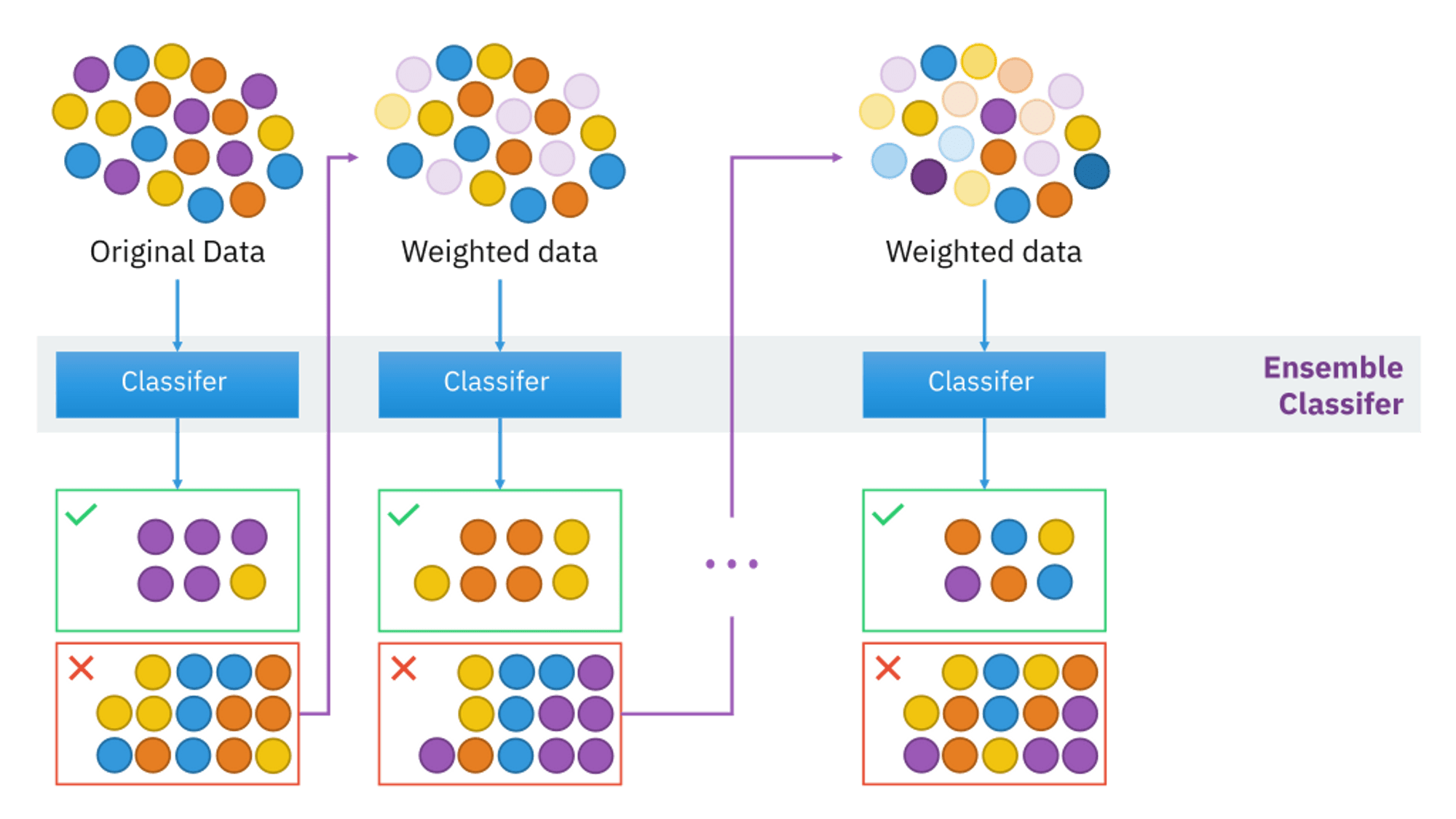
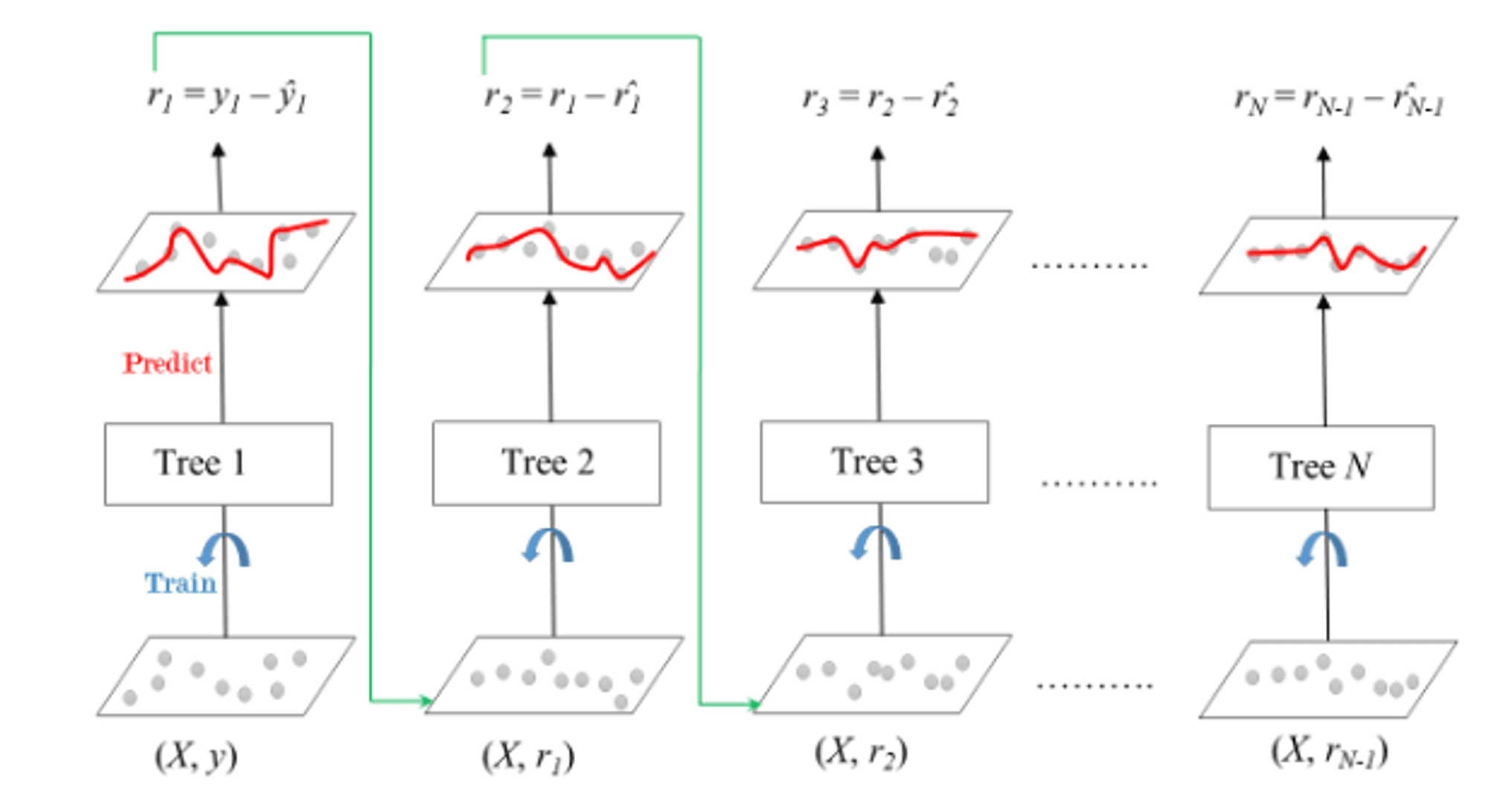
Выводы:
- Адаптивный бустинг (AdaBoost) присваивает веса точкам обучающей выборки в зависимости от того, правильно ли они были распознаны первыми классификаторами.
- Последующие классификаторы фокусируются на “сложных” случаях пропорционально весам.
- Адаптивный бустинг зачастую применяется для задач бинарной классификации.
- Граиентный бустинг (GBM) передает в последующие модели величину отклонения предыдущих моделей.
- Градиентный бустинг использует деревья решений в качестве индивидуальных предикторов.
- XGBoost - это параллелизуемая высокоэффективная реализация градиентного бустинга.
- XGBoost может обрабатываеть большие объемы данных.
- XGBoost склонен к переобучению, но использует регуляризацию.
- XGBoost достаточно требователен к объему оперативной памяти.
- Другие ивестные реалиации - LightGBM, CatBoost
CatBoost
Конвейеризация моделей
),
('clf', SVC())])
pipe.fit(iris.data, iris.target)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
numeric_features = [0, 1, 2] # ["vA", "vB", "vC"]
categorical_features = [3, 4] # ["vcat", "vcat2"]
classifier = LogisticRegression(C=0.01, ...)
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())
])
categorical_transformer = Pipeline(steps=[
('onehot', OneHotEncoder(sparse_output=True, handle_unknown='ignore')),
('tsvd', TruncatedSVD(n_components=1, algorithm='arpack', tol=1e-4))
])
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)
])
model = Pipeline(steps=[
('precprocessor', preprocessor),
('classifier', classifier)
])
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
simple_imputer = SimpleImputer(strategy='median')
std_scaler = StandardScaler()
pipe_num = Pipeline([('imputer', simple_imputer), ('scaler', std_scaler)])
s_imputer = SimpleImputer(strategy='constant', fill_value='unknown')
ohe_encoder = OneHotEncoder(handle_unknown='ignore', sparse=False)
pipe_cat = Pipeline([('imputer', s_imputer), ('encoder', ohe_encoder)])
col_transformer = ColumnTransformer([
('num_preproc', pipe_num,
[x for x in features.columns if features[x].dtype!='object']),
('cat_preproc', pipe_cat,
[x for x in features.columns if features[x].dtype=='object'])])
final_pipe = Pipeline([('preproc', col_transformer),
('model', model)])
final_pipe.fit(features_train, target_train)
preds = final_pipe.predict(features_test)
1
2
3
4
5
6
7
8
9
10
11
12
from numpy.random import randint
from sklearn.base import BaseEstimator, TransformerMixin
class CustomTransformer(BaseEstimator, TransformerMixin):
def fit(self, X, y=None):
return self
def transform(self, X, y=None):
# Perform arbitary transformation
X["random_int"] = randint(0, 10, X.shape[0])
return X
1
2
3
4
5
6
7
8
9
10
11
12
import pandas as pd
from sklearn.pipeline import Pipeline
df = pd.DataFrame({"a": [1, 2, 3], "b": [4, 5, 6], "c": [7, 8, 9]})
pipe = Pipeline(
steps=[
("use_custom_transformer", CustomTransformer())
]
)
transformed_df = pipe.fit_transform(df)
Выводы:
- Конвейер (pipeline) - это цепочка объектов sklearn, которая выступает единым объектом.
- Конвейеры нужня для автоматизации обработки данных и машинного обучения и построения простого воспроизводимого кода.
- Конвейер имеет единый интерфейс и может одной инструкцией применяться к разным данным.
- В конвейер обычно объединяют операции предварительной обработки, преобразования и векторизации данных, предиктивную модель.
- Модель обычно является последним этапом в конвейере.
- Конвейеры удобны для тестирования гипотез.